在人工智慧(AI)競速發展的時代,如何真正衡量智慧成為核心課題。ARC 基準測試(Abstraction and Reasoning Corpus)正是為此而生的一把新尺,它由 ARC 基金會 主導,旨在徹底改變我們對人工通用智慧(AGI)的評估方式。與傳統測試追求「知識記憶」與「狹隘專精」不同,ARC 測試的核心哲學在於評估 AI 的 泛化能力 與 學習效率 —— 亦即像人類一樣,從少量範例中快速理解並解決全新問題的能力。
ARC 基金會的使命:引導AI走向真正的智慧
ARC 基金會是一個非營利研究組織,其使命深植於AI研究員弗朗索瓦·肖萊(François Chollet) 的理論框架。肖萊在其頗具影響力的論文《關於智力的衡量》中,將智力定義為「適應效率」,即在陌生情境中有效學習和解決問題的效率,而非靜態知識的總量。基金會據此理念,致力於推動AI研究社群超越狹隘的基準優化(即「刷分」),轉向開發具備廣泛適應性和推理能力的系統。其核心工具,便是持續演進的ARC基準系列。
ARC 基準的演進:從靜態謎題到互動世界
ARC基準的設計,旨在迫使模型展現抽象推理與歸納能力。
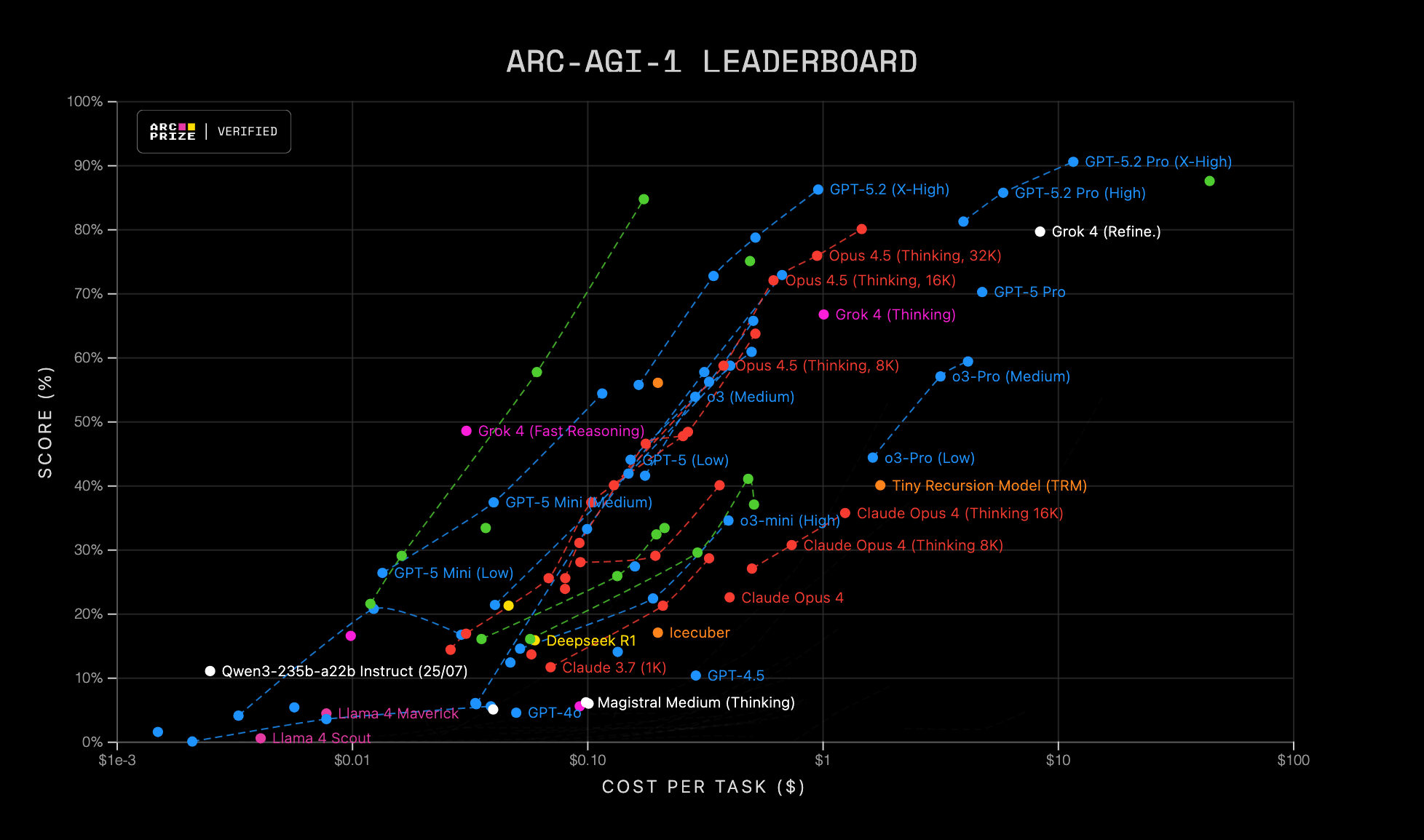
- ARC-AGI 1 (2019):這是肖萊親自創建的原始靜態視覺謎題集(約800個任務)。每個任務都提供少數輸入-輸出範例,模型必須推斷出背後的抽象規則,並應用到新輸入上。此基準明確排除了依賴預訓練數據記憶的可能性。您可以透過官方介紹了解其最初設計。
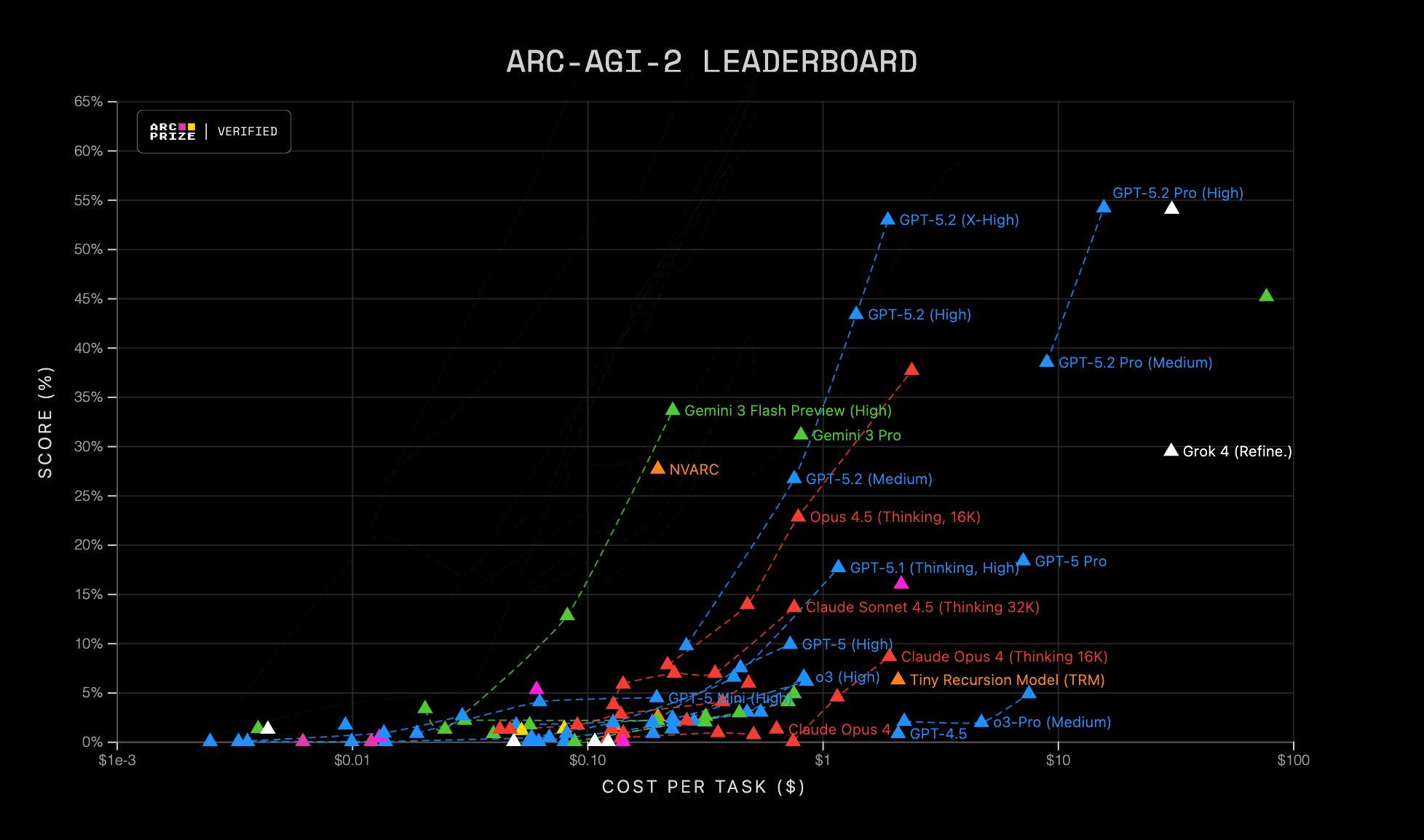
- ARC-AGI 2 (2025):作為第一版的進階,它強化了任務的複雜性與深度,但同樣保持「靜態轉移測試」的性質,繼續挑戰模型的模式歸納能力。
- 未來方向:ARC-AGI 3 (互動式基準):這預示著評估範式的巨大飛躍。根據基金會展望,ARC-3將不再是靜態謎題,而是一個包含約150個類遊戲環境的互動世界。AI代理人將在沒有文字說明的情況下,僅透過行動(如上下左右)和環境回饋,自行探索、推斷規則與目標。這將直接測量其互動數據效率,並與人類解決同一謎題所需的行動次數進行比較,使「學習效率」的衡量變得具體可量化。
為何主流實驗室都重視ARC評估?
近年來,從 OpenAI、Google DeepMind(在其Gemini及DeepSeek技術報告中)到 xAI(如Grok系列)等頂尖實驗室,均在模型發布時例行報告ARC-AGI分數。這標誌著ARC已成為評估模型核心推理與泛化能力的關鍵標準,與傳統的知識型測試(如MMLU)形成互補。一個在MMLU上表現超群的模型,可能在ARC上舉步維艱,這恰恰揭示了當前AI系統在根本推理能力上的短板。
對AGI研究的深遠意義
ARC基金會認為,解決ARC基準是邁向AGI的必要但不充分條件。一個能在此測試中達到人類水準的系統,證明它掌握了強大的歸納與適應技能,這無疑是AGI的核心支柱之一。基金會的目標正是透過這個不斷演進的基準,持續引導研究社群聚焦於泛化與效率這兩個根本課題,避免陷入短期的「指標遊戲」。
總結而言,ARC 基準測試不僅是一個評估工具,更是一種研究範式的倡議。它挑戰我們重新思考智慧的內涵,並為通往更通用、更高效能的人工智慧,鋪設了一條以「學習如何學習」為核心的清晰道路。
Source: https://youtu.be/pBlIgs6w7Ss